Model Your Content
Summary
Content takes many shapes and connects in many ways. How these shapes and connections manifest – both in how they relate to the editorial and design model and in how they are converted into data that a content management system can manage – has considerable impact on every subsequent stage of the project.
Does This Apply?
While the technical side of content modeling is focused heavily on building connections within a content management system, the concept of content modeling applies to any situation. It’s important to understand how content will be understood by both the content management system and any external resources, and even hand-coded boutique sites need to know how the pieces of a specific page are interpreted on different mobile widths or by different search engines.
Narrative
If you watched cartoons, game shows, or soap operas in the early 90s, you might have seen an advertisement for Better Blocks.

Episode 11: Model Your Content (w/ Jeff Eaton)
Corey and Deane chat about the first time they realized they really liked content modeling, and how modeling is the hidden language of content. Then, Jeff Eaton, partner at Autogram, joins to define content modeling, the concept of content reuse (and its many issues), and the balance between philosophical modeling and actually doing the work in spreadsheets.
Defining the Content Model
If every piece in a building block set is the same, there’s no inherent way to determine which one goes where. Unique function leads to unique forms, and those unique forms help guide us toward understanding purpose.
This is what happens inside your website. Your content, no matter how hard you’ve worked on it or how strongly you feel about the subject matter, is just data to a content management system. It’s an amorphous blob of characters and images, mushed into the cells of a database in some cloud environment. It’s a pile of similarly shaped bricks, and your content management system doesn’t know what to do with any of this data until you tell it what it is, how it works, and where it should go. Until you shape it in a way that communicates its purpose.
This is the work of content modeling. A content model, according to Deane’s Web Content Management: Systems, Features, and Best Practices, is:
“A conceptual term for the collection of content types, attributes, relationships and datatypes in place to accurately describe a logical domain of content.”
The idea of a content model can feel a little abstract, because it balances between the conceptual idea of content – the organization and strategy that we’ve talked about in the last two chapters – and the functional structure of that content. Jeff Eaton, in his presentation “Maps, Models, and Teams: Content Modeling as Collaboration,” defined content modeling in simple terms as:
- What kinds of things we make
- How they relate to each other
- What bits of info they contain
In other words, content modeling defines the container within which we will place our content. Elements within a content model fall into two types:
- Discrete: the self-contained internal structure of an object – e.g., the fields within a content type, like a sub-title or author name.
- Relational: how an object of the type relates to other objects – e.g., a category assignment or aggregation.
For example, take the standard “article” content type. An article has a set of unique fields that manifest as content on the page – discrete elements, such as title, subtitle, author name, main body, or publish date. An article also contains several relational elements, such as how it automatically pulls into a news feed, or how assigning a specific category allows that page to show in a related feed1.
The Content Model in Action
Of course, the actual concept of content modeling means different things to different people. To those leading a web project or planning and managing a website, content modeling is focused on defining and maintaining the templates needed to serve your unique content needs. To those designing
a website, content modeling is focused on visual representation of content types, including the structure of content at different screen widths and within applications. To those building a content management system, content modeling is focused on defining the parameters in which content will work within a template.
In reality, a content model helps streamline the editorial process. It helps us create:
- Content reuse: Instead of repeating the same content over and over again, we rely on relationships to “reuse” content from other sections, such as programmatically created lists based on categories.
- Intelligent content management: Because the content model assigns meaning to pages, components, and fields, the robots in your content management system understand what to do and where to go.
- Freedom for content beyond the content management system: Data connected to your content model informs both current applications and external applications, either through API2 or some other kind of data transfer. Multichannel publishing is not possible without a well-defined content model.
Understanding Adaptive and Structured Content
While the content model is largely responsible for defining and providing connections between content types in a single content management system, it also provides us with the tools to begin shaping our content beyond the standard page. This is where terms like adaptive content and structured content come into play.
- Structured content describes the process of breaking a single content type into individual attributes or fields, allowing these fields to be delivered to different places at different The classic example is a recipe: a recipe is not just a blob of words, but instead a set of unique parts (recipe title, cooking time, individual ingredients and their amounts).
- Adaptive content uses structure to adjust what content is displayed based on the device or environment3. Sometimes this is design-related – responsive and adaptive design rely heavily on structured content to help maintain the content’s meaning while rearranging design based on screen width and speed – and sometimes it’s personalization, such as when a site like IMDb serves different content based on whether you are logged in or not.
For example, think about how a specific episode preview of Parks and Recreation on a streaming service might provide a season number, an episode number, a title, and a summary. This is adaptive content being uniquely displayed on the preview page, fueled by the unique structured content fields within the larger content system.
If you imagine creating a page within your website, anything outside of a rich-text editor4 or not hard-coded into your page template is, in some small way, structured. There’s irony in this, as noted by Rachel Lovinger and Razorfish in their white paper “The Nimble Report”:
Ironically, it’s more structure that makes content nimble and sets it free. Not the kind of blind structure that defines the layout of a web page, but tags that express the meaning and function of each individual element in a content item.
Planning the Content Model
You can do nearly anything with your content if the content model is developed in the right way. That’s the difficulty, of course: a content model does not live in a vacuum. You can dream as much as you’d like, but if it does not fit what your tools can actually manage, the content model’s promise of an interconnected editorial experience will fall flat.
Connecting Objects
Of course, part of that dream is to actually begin mapping out what your site needs to develop a real model. What kinds of things are necessary to communicate to your audiences and provide closure to their expectations?
For example, let’s imagine you run a record label, and that users are coming to your website to purchase merchandise for one of the artists on that label. From right here, we can start sketching out the types of things they’ll be looking for. For example, digging down into the information necessary to sell an artist’s music we find that:
- Each individual artist is its own object
- Each artist has a set of albums
- Each album has a set of formats (vinyl, CD, cassette, digital)
- Each digital album has a set of songs
Another branch is formed if we dive into artist merchandise:
- Each artist has merchandise
- Merchandise can be organized by media type: album, by tour, by type (shirt, pin, sticker)
- Each shirt has a set of parameters (size, color, style)
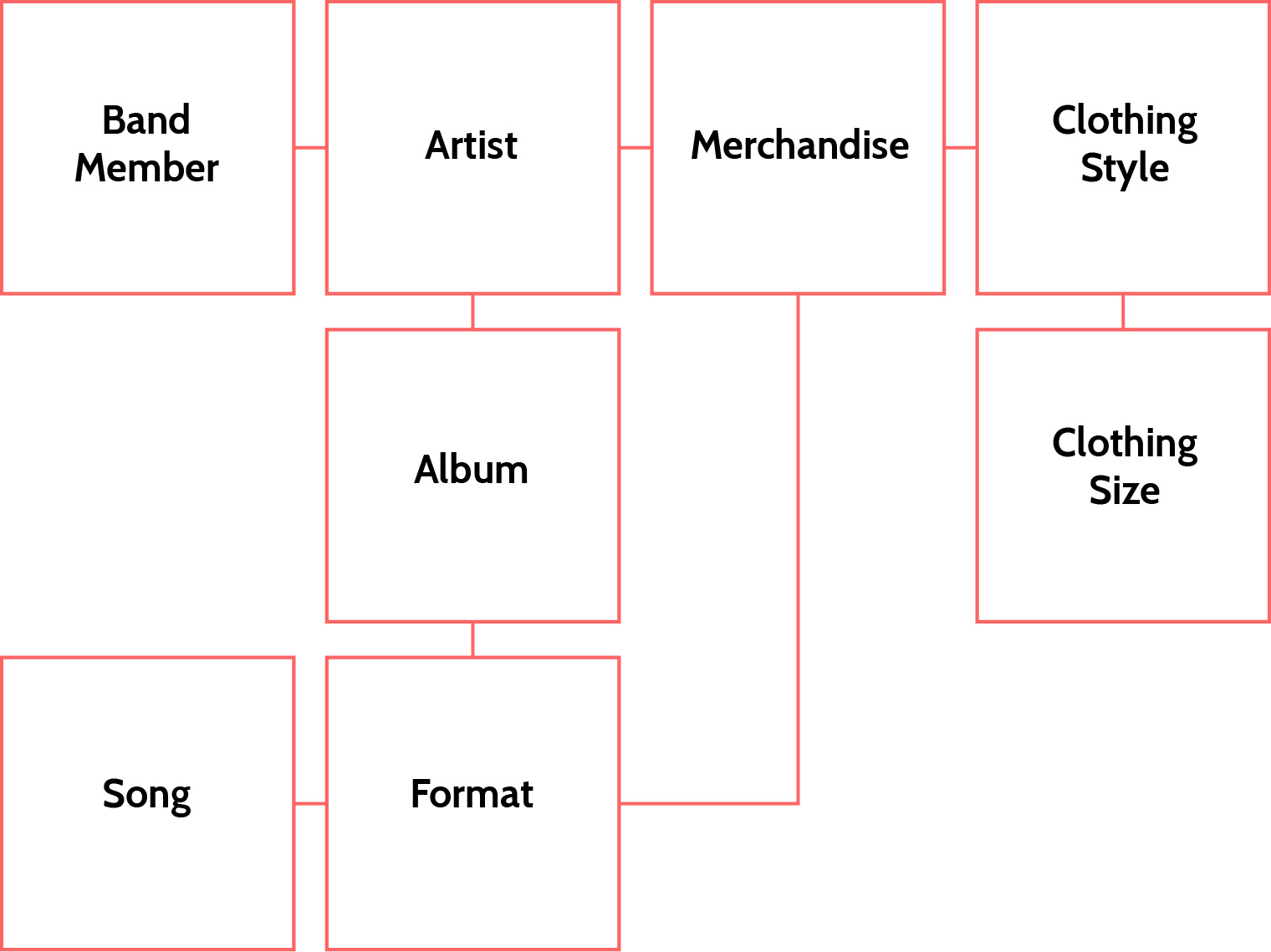
Figure 11.2: Connecting Elements of a Record Label Website.
What’s more, each artist might have an artist bio, an artist discography, or tour dates. Each of these might be structured in a way that they show on the artist’s product page, or even on every individual product. The artist might show in certain sections if they’re still active (versus being retired or currently signed to a different label). Those tour dates may trigger an artist to be “featured” on the home page.
This isn’t to say every content model will go this deep – instead, we’re highlighting how each object is a unique piece of content, and how they connect is largely dependent upon a balance of technical complexity and editorial workflow.
Balancing the Content Model
With the general concepts defined and some basic list of content types created, we look then to the language of templates.
We often think of our websites as collections of pages, each one unique and focused on one specific chunk of content. In reality, for sites run on some kind of content management system, websites are patterns of templates.
Each template relates to a specific kind of content, and is created to uniquely serve that kind of content. The content inside is, in a way, a series of answers to a long list of questions.
Take a news article, for example. The template helps define a publish date, and an author. It may provide a different visual layout, or provide unique layouts for different situations. Or, these templates may represent a small section
of a page that can be dropped and reused on multiple pages – a block, or a component. These templates might even represent a simple definition, such as when we define the categories that might appear on a list of products.
Within a content management system, we see, essentially, four categories of content templating:
- Pages: Pages are what you see5. They are often URL addressable, and more likely to be larger and more complex templates, with a common set of unique fields. An example is a university professor’s profile page.
- Blocks: Sometimes known as modules or components, depending on the CMS. These are unique content chunks that are not assigned to a specific URL and are designed to add customizability to existing content pages. An example is a video block that can be placed on that university professor’s profile page.
- Aggregations: These are feeds or collections of content already created within the CMS, reconstituted for a new purpose. An example is a university faculty directory: outside of the request to list and sort all faculty members, none of the content for the directory actually lives on that page – it’s all aggregated from the existing profiles.
- Integrations: These are pulled into the CMS from a completely external source. Integrations are often completely and totally out of the control – outside of design and parameters – from the CMS itself. An example is an integration of content from Google Scholar onto a professor’s profile page.
This is all mentioned to show that there are tons of connections to consider in order to replicate the understanding we as humans already possess.
A well-modeled site is created in a way that approximates the connections our brains already understand, which is why we find ourselves frustrated with a poorly modeled site: we assume that some kind of knowledge, whether it’s how a news feed is displayed or what shows up in search results, is so common that it should be present.
Balancing this content model requires just as much thoughtful user-focused design and domain knowledge as its fancier siblings in content and graphic design. In her book Content Everywhere, Sara Wachter-Boettcher urges us to consider our content model against three criteria:
- Gains and losses: What do you gain by making something its own piece of content keeping it as a piece of a larger template?
- CMS capabilities and trade-offs: Will your content management system support extra complexity, or will it slow down the entire site?
- Authors and workflows: Will content creators and editors find the extra structure or added content types to be helpful, or will it hurt productivity and morale?
Common sense needs to be programmed, and it can be one of the most difficult things to do because we’re making assumptions about what a CMS knows the second we encounter it. Until the content model is actually implemented, however, the connections and concepts therein are nothing but a dream. Just as a schematic diagram accomplishes very little without real physical connections, a content model needs to be defined within the content management system through code.
Implementing the Content Model
With the objects determined and the overall model sketched out, we can start defining things for both editors and the content management system. Largely, this falls into documentation and creation of attributes within each content type.
Content attributes fuel what you see on each page. If you imagine a single page on a website, you can imagine it as the arrangement of multiple unique attributes: title, main body, related items. But content attributes also fuel the connections between content types. They provide guidance behind the scenes, in the metadata and content aggregations.
For most content types, a majority of the attributes will be easy to uncover. An album page from our music example above will have a field for title, artist, album image, description, track listing, and price. Determining what feeds into each of these attributes is a bit more complicated:
- Title: A standard text string, or a “fill-in-the-blank” field.
- Artist: Chances are, a content type related to artist already exists, so you would add the relationship in this field. In this sense, you’re not typing in a random text string; instead, you are saying “when I say artist, I mean this artist object.”
- Album Image: An uploaded image. This could pull from a central library, or it could be connected to this individual page.
- Description: A rich-text (WYSIWYG) field that may include links to other content on the site.
- Track Listing: This might be rich-text. Or, it might be a content relation to each individual track (if they’re available on their own).
- Price: A standard text string, or potentially a tie into an existing sales catalog.
As you can see, populating the attributes in a content model is not as simple as a fill-in-the-blank form. In Rachel Lovinger’s A List Apart article “Content Modeling: A Master Skill,” she says that for each attribute, you must consider the following:
- Layout: Do some things need to be displayed in a completely different style, or in varying places on the page? Avoid having markup and styling stored with content – instead, if different layouts break up content in different ways, break them out into unique attributes.
- Reuse: Again, a separate field of data can be pulled out and used independently of the rest of the page, but not if it’s all part of one big body of text.
- Sorting and filtering: If you want to be able to sort content by date, or filter content that pertains to a particular city, then these pieces of information have to be in a field by themselves so that they can be used to sort and filter.
Implementing Aggregations and Automation: Using Categories and Metadata
We talk a bit in Chapter 12: Write for People and Machines about writing for metadata – writing text that can be used beyond the page itself to help populate search engines and identify important concepts. Here, we’re talking about metadata as classification – a guide to helping content get to where it needs to be, often behind the scenes in a way we’ll never formally encounter.
For example, let’s say we’re in need of a news feed on our site. We all know what a news feed is: it’s a list of news articles, usually in reverse chronological order. But to the content management system, that news feed is a kind of saved search, filtered by a set of parameters. It’s up to us to define the parameters. Some of this happens in development, as the page is created within the content management system, while some of it happens editorially and is assigned, either during programming the content type or as an editorial task. For our news example to work, we need to make the following programmed choices or editorial decisions:
- Program the news feed to only pull content of a specific content type – in this case, a news article.
- Determine what structured content within that content type will display on the feed – in this case, the title, article summary, publish date, and author.
- Create a rule for feature articles that allows an editor to flag an article as “feature,” which means it will appear at the top of the page layout.
- Create rules for how to handle the news feed if more than one article is flagged as “featured” – do you show all featured articles at the top, or only the most recent6?
- Determine the default number of article previews per page, and paginate beyond that. Is this hard-coded into the content type, or can an editor change that number?
This combination of human editorial metadata – curation by data, in a way – and programmed relationships is the ultimate promise of a well-balanced content model.
Structured and Semantic Content
Semantics is the study of “meaning,” and for the web it means helping complex systems understand the meaning of words and concepts. Again, content management systems don’t understand human language, so we have to define languages in a way that they understand: through connections and data.
In some sense, we’re still talking about metadata – managing semantic content means assigning metadata like “location” and “people” and “date” – but when we talk about structured language and semantic content, we’re looking at something called XML – extensible markup language – which helps provide meaning and structure within our templates. In the words of Rahel Anne Bailie and Noz Urbana in their book Content Strategy, “XML explains to computers what humans immediately know about content just looking at it.”
From a technical standpoint, building this XML into a specific page template is the work of back-end developers. However, it’s a full-team process to determine what schema to use and which XML elements to incorporate.
There are universal schema developed for dozens of industries and organizations that help identify content types and data types for purposes beyond a web browser, including creative works like books and albums, health and medical data, and even how reviews and ratings are handled.
Additionally, there are proprietary schema that exist outside of XML, specifically focused on aggregation of content within social media or search results. These include Google’s structured data and Opengraph.
Developers will integrate XML within the standard markup of a page – the HTML, or the basic structure of content and design recognized by web browsers – and very little of it is going to be interpreted by actual humans. This is all behind-the-scenes stuff.
Beyond Structure: Writing Still Matters
Implementing the content model and creating the vehicle for your content is an exercise in balance and deconstruction. You work backwards from a finished product in order to figure out how things fit together – and how far you’ll need to break it apart.
Of course, this is only tied to the content you can fit within a unique attribute. Beyond that is the actual words themselves – not just what a title is, but how that title is written. Not just the content in the main body field, but how that main body field matches user expectations and drives action on your site.
Structured data and content modeling is important to help keep your content intelligent, mobile, and free. But that content isn’t worth anything if it doesn’t connect with your audiences. In the next chapter, we’ll take a deeper look at writing for the web – the methods, the rules, and the myriad of possibilities you’ll encounter as you go from dream to reality.
Inputs and Outputs
For content modeling to work, you need to understand the technical goals of your site. You cannot build a content model for a calendar, for example, unless you understand the types of events you’ll be promoting and the browsing patterns of those who will attend. You’ll also need to know if there are any standards in your industry or organization that need to be followed. Finally, you’ll need to have some basic understanding of how your content management system will handle certain types of content.
As a result of the content modeling phase, you’ll understand the scope of what is necessary for front-end and back-end development. You’ll have identified the full suite of templates and their attributes, and you’ll have a stronger sense of who will manage (and how they’ll manage) the content for your new or revamped site.
The Big Picture
Content modeling tends to pull from both the strategic content process and information architecture in that it takes the strategic and organizational needs of your site and builds a model by which you can reach your content goals. At Blend, we often tackle content modeling as a part of our larger content management scoping process – knowing the templates and aggregations of our site helps us get a better grasp on how much time design and build will actually take.
Staffing
Content modeling requires a mix of content strategy, information architecture, and content management system development. It’s a transition period that’s most often staffed either by someone who understands how a content management system works, but in a way that takes an editor’s experience into account.
Resources
Articles
- “Content Modelling: A Master Skill,” A List Apart, by Rachel Lovinger
- “What is Content Modeling,” by Cleve Gibbon
- “What’s the Deal with Structured Content?,” Gather Content Blog, by Rahel Ann Bailie
Books
- Designing Connected Content by Mike Atherton & Carrie Hane
- Content Everywhere by Sara Wachter-Boettcher
- Content Strategy for Mobile by Karen McGrane
- Metadata by Jeffrey Pomerantz
- Web Content Management: Systems, Features, and Best Practices by Deane Barker
- Real World Content Modeling: A Field Guide to CMS Features and Architecture by Deane Barker – (coming soon)
- Intelligent Content by Ann Rockley, Charles Cooper, and Scott Abel
Files/White Papers
- The Nimble Report by Rachel Lovinger
Presentations
- “Adapting Ourselves to Adaptive Content” by Karen McGrane
- “Maps, Models, and Teams” by Jeff Eaton