Implement the Back-End Functionality
Summary
This is a deceptively simple step for what amounts to actually building the inner workings of the website. You need to examine site functionality, break it into manageable iterations, and plan how it all will come together.
Does This Apply?
You’re almost always going to have to do this at some level, but the depth depends on the system. Some systems will be implemented from code and deployed via DevOps, and other systems will be just configured from an interface.
The only time that there’s no backend implementation required would be a highly pre-packaged system for a known, controlled use case (a simple blog, for example).
Narrative
If you want to build a house, you can visit your local building supply superstore. They literally have everything you need. They have lumber, plumbing, electrical wiring, shingles, windows, and doors. They have hammers. They have toilets.
All you have to do is wander around, fill up your shopping cart, pay for it, and schedule delivery. They’ll be happy to put everything on a truck and deliver it to a patch of dirt that you own.
But when you go to live in that house you bought, you’ll find there’s no house. There’s just a bunch of stuff stacked on the dirt. Because – obviously – you didn’t buy a house, you just bought the materials to make a house. Even if you thought ahead and bought some prefab walls, they still aren’t bolted together to make a room.
You bought a potential house; without a human being to put it all together – to apply some knowledge and a lot of effort – it will never reach that full potential.
At some point, someone is going to have to coerce a CMS into doing what you need it to do. Most CMSs can publish content in some form out-of-the-box, but they have to be persuaded to do it in a way that fulfills your requirements.
“Coerce” and “persuade” might seem like weird ways to put it, but the backend development of a CMS is really a process of bending a tool to your needs. Sometimes it’s very close – so the influence just needs to be slight – but sometimes it’s wildly off and you need to apply more pressure to get it where you need to go.
Also, there’s a sometimes blurry line between web development and CMS implementation. “Pure” web development would be programming from scratch, rather than building on the base of a CMS as a platform. Think of a CMS as the prefab walls of a structure. Rather than building each wall from nothing but wood and nails, you just need to bolt some existing things together. There’s still quite a bit of development that comes into play, but the CMS should handle a lot of the routine work of processing managed data.
In the sections below, we’ll assume you’re working with a competent web development team. What we’re outlining here are the terms and concepts you’ll need to understand to communicate with that development team as they get your CMS to model, aggregate, manage, render, and publish your content.

Episode 20: Implement the Back-End Functionality (w/ David Knipe)
Corey and Deane discuss a high-level philosophy of back-end development. Then, David Knipe, Vice President of Product at Optimizely, joins to discuss back-end development — how developers and project stakeholders work together to make decisions, the difference (and balance) between technical perfection and audience needs, and the reasons why AI will help, but not take over, back-end development. Deane also equates developers to lumberjacks.
Model Implementation
In Chapter 11: Model Your Content, we discussed your content model, or how to represent your content in a way that maximizes your ability to present and reuse it. Now you have to convert that model into something your CMS can manage.
We’re going to call this a model implementation to separate it from the model in theory. The model implementation is your content model working inside your chosen CMS. It’s how the idea of an “article,” for example, becomes an actual article on the site.
In practical terms, a model implementation is a combination of these things, which are fairly universal:
- Types: The specific types of content. Each content type is a named combination of multiple attributes. For example: “Article.”
- Attributes: A specific piece of managed data. A unique combination of attributes forms a type. For example, an article content type usually includes attributes like “Title” or “Publication Date.”
- Datatype: Each attribute has a datatype that limits the data which can be stored by it – for example, the “Text” attribute may only allow for an unformatted string of characters.
- Validation Rules: A rule enforces the datatype – or confirms there’s data at all – in specific attributes. For example: the “Title” attribute may only allow 250 characters, or the “Author” attribute may be required.
These three things need to be created and configured inside your CMS, usually from an administrative interface or – more commonly, these days – from code1.
There are several goals to the model implementation.
- Descriptiveness: The model implementation needs to describe your content at a level that allows you to manipulate and output it effectively.
- Usability: The model implementation will drive your CMS’s ability to provide your editors with both usable interfaces to manage it and logical relationships.
- Resiliency: The model implementation needs to keep your content safe and valid, and prevent editors from storing content in an invalid state.
The achievement of these goals is not binary – it’s not like your model implementation is “descriptive” or “not descriptive.” It just gets closer or further away from an ideal. You’ll usually never get all the way there (if it could even be objectively defined).
Why shouldn’t you always attempt full realization of that ideal? Because every model implementation is a balance between complexity and flexibility. A key point when implementing your model in a CMS is deciding how far to take it.
For example, you may dictate that every instance of an “Employee” type includes dozens of fields, all of which are required. This leads to a rigid, structured content type – good in some cases, bad in others. On the other hand, perhaps the “Employee” type is just a rich-text (WYSIWYG) field. We’ve increased flexibility, but at the expense of structure. Editors have it easier, but the CMS no longer has the explicit definition of each field that came from the structured content.
You might try to handle every possible edge case and theoretical situation, but the result would be too complex for your editors to work with. The stricter your model implementation becomes, the more friction it introduces to the editorial process. You need to decide how strict this needs to be.
Additionally, your CMS imposes limits. And sometimes they’re unfortunately arbitrary and final. In a theoretical model, anything is possible. However, CMSs have specific feature-sets around content modeling – they’ll no-doubt support some aspects, but might struggle with others.
Not Every Model Can Fit
Your ability to accurately represent your model depends on the modeling capabilities of your CMS, but also on the creativity and experience of your development team. Given enough experience with a specific CMS, a developer will learn what all the traps are.
Any developer experienced in a CMS should be able to look at your requirements and mentally formulate solutions to 90% of them, while the more advanced problems might require prototyping, or even trial-and-error.
And, sometimes you just can’t wrap a CMS around your model requirements. For example:
- An “Article” requires a link to an “Author” This is supported, and it allows readers to see who wrote an article, then find their author page. However, what if your CMS doesn’t consider this link to be bi-directional? Now it’s not possible to perform the opposite action of seeing a list of “Articles” on the author page.
- A “Meeting” object requires “Topics.” Each “Topic” is also a content object, which means you need to connect a “Topic” to a “Meeting” in a parent-child relationship. However, what if your CMS doesn’t have a content tree that would allow this? Now someone else could link another “Meeting” to the same “Topic” (not allowed by the model), and it won’t stop a deleted “Meeting” from “orphaning” a bunch of “Topics” (also verboten).
These examples might seem weirdly specific, but they’re accurate examples of where content models run into problems. Even the simplest modern CMS allows the definition of structured types – that’s the easy part. The problems crop up at the edges, where you had an idea that seemed simple in theory but becomes infuriating in practice when you simply can’t wrap your CMS around it. You try to “fit” your idea in multiple ways, but the CMS seemingly thwarts you at every turn.
Model implementation is a process of concessions. Consider our second example from above, and here are some ways you might get around those limitations.
- You might decide that someone could link a Topic to two Meetings, but that’s just a thing you’re gonna have to live with. Maybe you educate your editors to just not do this, or create a report that shows you when this happens, so you can correct it.
- You might limit the deletion of Meeting objects by permissions, restricting it to administrators (or even just a single master editor) who know better than to orphan Topic objects.
- You might have a developer create some code to unlink a Topic from a Meeting when it’s linked to a different meeting, or automatically delete all related Topics when a Meeting is deleted.
Two of these options tie to governance, not programming, while the third is more of a complex workaround. The reality of your CMS’s capabilities can be a wet blanket, but it’s something most projects encounter at some point. The flexibility of a theoretical model often clashes with reality.
Editorial Experience
One of the goals of the model implementation we explained above was “descriptiveness.” You need to describe your content to your CMS.
Let’s take a trip into the Theater of the Absurd. Imagine sitting at a whiteboard with your CMS, and drawing it out so your CMS understands what the different types are, how they work, and why this matters. Consider this imaginary conversation with your CMS:
You: Okay, now an Article has a Published Date …
CMS: I’ll show a date picker for it, but does it need a time?
You: No. No time.
CMS: [takes notes] Okay, I won’t show the time selector then. Can the date be in the future?
You: No.
CMS: [furiously scribbling notes] Okay, I’ll prevent them from entering a future date.
As you describe your content more carefully, the CMS can use aspects of its UI to force or coerce editors to enter correct data.
- Data Coercion: The usage of editorial elements to prevent the entering of invalid data. For example, the usage of a date picker, or the elimination of the time selector. By doing these things, the UI is actively preventing invalid data from being entered. There is just no other way.
- Data Validation: Sometimes, an editor can enter invalid data, but the CMS can prevent it from being saved or stored by validating the published date to be sure it’s in the past. If it fails validation, the CMS can show an error message and require the editor to change it.
Let’s continue the conversation:
You: I want them to be able to format this text.
CMS: I can display a rich text editor. Can they do anything they want?
You: No, just bold, italics, and linking. No tables or anything like that.
CMS: No worries. We’ll only show them buttons they can use.
Limiting or “neutering” rich text editors is a critical aspect of editorial experience. As a general rule, only show editors things they can use.
You: Okay, now if they don’t enter an “SEO Title,” we’re just going to use the regular title.
CMS: Got it. We should tell them that. I can include a message under the field so they know.
Accurate labeling of form fields is critical, both in the simple label and any extended help text. Every field should have clear instructions of how it relates to the model.
You: This is a lot of fields. This might be confusing.
CMS: Tell me how they relate. I’ll put them in tabs.
The simple grouping of fields under tabs or collapsible headings can help enormously in limiting the cognitive overhead of perceiving a giant page of form fields.
In each case above, we’re describing our content model more and more, which is enabling our CMS – or, more specifically, the team in charge of implementing your CMS – to make our editors’ experience better and better. Most systems will have these features built-in, but they logically require an understanding of the model to be manifested – a CMS can’t just decide how to group fields; you need to tell it. Generally speaking, the more you describe your model, the better the experience can be.
Projects tend to concentrate on the visitor experience, and gloss over editorial experience, to their detriment. Happy editors make better content, and a shocking number of CMS re-implementation projects have started from the same sentence: “Our editors hate using our CMS.”
Cater to your editors. Implement your content model at a level that allows the CMS to help them. The happier they are, the better your content will be, and the longer your CMS implementation will last.
Aggregations
As we discussed in Chapter 11: Model Your Content, content objects don’t exist in a vacuum. They usually have to be organized into larger structures in order to provide some value.
Every CMS will offer a toolkit of features to manifest your logical model aggregations. One of the key skills in working with any CMS is knowing what these aggregations are, and their relative advantages and drawbacks, so you know when to use one over the other.
Some common aggregation tools:
- Content Tree: A very common pattern is a “tree” of content, where you have a “root” object with a hierarchy of descendants below it2. Every object is a child of another object, and might have one or more children of its own. This is a very common way to organize content and overlays naturally on navigation and website organization. For many systems, this is the main organizational method for content.
- Folders: Occasionally a system will organize content by containers, often visualized as “folders” to piggyback on the visual model of most operating systems. In a way, this is also a parent-child structure, but parents can only be of a specific type (the folder), and these folders often do not manifest as content on the site.
- Menus or Collections: Most systems will also have some arbitrary method of organizing and ordering content into serial lists or hierarchical menus. In some cases these are literally meant to be web menus (sometimes with pre-built HTML)3, in others cases they’re just meant to structure content so it can be accessed in some group via code or from templating. A key point here is ordering: both these aggregation methods allow you to put content in an explicit order.
- Tags or Categories: As we discussed in Chapter 10: Organize Your Content, it’s also common for some method of tagging or categorizing content. The two methods are very similar, but categories are usually created in advance by someone responsible for maintaining the organization structure, and they can often be organized into a tree. Conversely, tags tend to be ad hoc, so editors can make them up on the fly.
The differences between aggregation methods can be subtle, and there’s often a lot of overlap. A hierarchical menu structure is very similar to a content tree. And tagging or categorizing content can seem very similar to putting content in a collection.
The choice to use one over the other can come down to some very subtle factors, and tragically, these factors might not surface until after the system launches and is in production. Months down the road, your editors might be frustrated or have come up with some particular use case that a certain aggregation doesn’t handle well, and to fix it, you have to back out large portions of the system and re-work them using a different aggregation method.
Your developers will use content aggregations to build out the basic framework of your site. Your content model, even when turned into a concrete model implementation, is still just theoretical until it starts filling up with content and those building blocks are stacked, via content aggregation methods, into some sort of framework to form a larger domain of information.
The actual aggregations that come out of this process might be used to:
- Form primary navigation (ex: the main, overhead navigation, or a “super footer”)
- Create localized, sectional navigation (ex: “In this Section”, or “Our Products”)
- Create index pages, or lists of content (ex: “Latest News”)
- Create topic-based indices of content (ex: “Articles About China” or “Related Content”)
Content Rough-In
Even once the model implementation is in place, the content is still very theoretical. A model implementation is a framework or container for content, but there’s nothing in it yet.
Your developers will usually have to go through some explicit stage of “rough-in” where they add some content to the system. They’ll need to do this both to test the model implementation – what works; what doesn’t work – and to confirm that aggregations work as expected. It’s hard to figure out if a particular aggregation will work for the main navigation unless you create it and work with it.
Content rough-in is not migration. You might test some migration methods by moving some content and using that (highly recommended, in fact; nothing works like real content), but often a developer will just enter some “junk” content to provide some building blocks to the system.
When the model implementation is in place, the aggregation methods are created, and content rough-in has provided something to put in structures to create the basic “shell” of a website – that’s when you can really begin to see how things come together.
Templating and Output
In Chapter 19: Implement the Design, we discussed front-end development and gave some examples of HTML. What we didn’t explain is how your content comes to be mixed in with that HTML. Static HTML doesn’t help – we need HTML that changes to represent the different content in our CMS.
This happens through some process of templating, whereby static HTML is mixed with dynamic content to form output. A template provides a starting point for output – it’s usually a mixture of HTML and special programming code that injects data from a content object to generate a specific output. Apply Content Object A and you get a certain output; apply Content Object B and you get a different output.
Templating features come in a few forms:
- Token Replacement: The most basic form of templating, in which HTML is formed as a structure for a page, and code snippets called tokens are placed in the right spots — a token where the title goes, a token where the main body goes, and so on. Your content then replaces those tokens in the template, and the page shows up with all of your words and images.
- Output Filtering: In this style of template, content is filtered into a template and changed in some way. For example, you may want to pull in content and display it in all caps. An output filter added to a specific field will template that change. Or, you might filter based on an argument, such as displaying a date in a specific way different from the raw data.
- Looping: Your template might have a piece of data representing a collection of objects, and it can repeat a section multiple times. For example, the loop for an article listing will create a list of all articles, over and over again, in a loop, until it reaches the end, whether that be five articles or five hundred.
- Conditionals: These allow you to make decisions about whether or not to do something. For example, you can add a conditional that suppresses a field if it is blank (such as if an article has no selected author).
These four constructs – token replacement, filtering, looping, and conditionals – are the basis for most every templating language. Using these things, a developer can take content data and form HTML output.
Request Mapping and the Operative Content
We introduced the request-response model of the web in Chapter 17: Plan for Hosting. Remember that a web content management system responds to requests. Someone inputs a URL in their browser and some HTML is returned.
In most CMSs, specific content objects get assigned URLs when they’re created. The URLs are often based on the type of content, or where the content sits in a content tree (each object gets a segment, and the segments of all the ancestors back to the root object form the URL).
Regardless of method, content objects which are intended to be directly addressed by a URL know what URL they should respond to.
Given this, here’s how the request-response model plays out for a CMS.
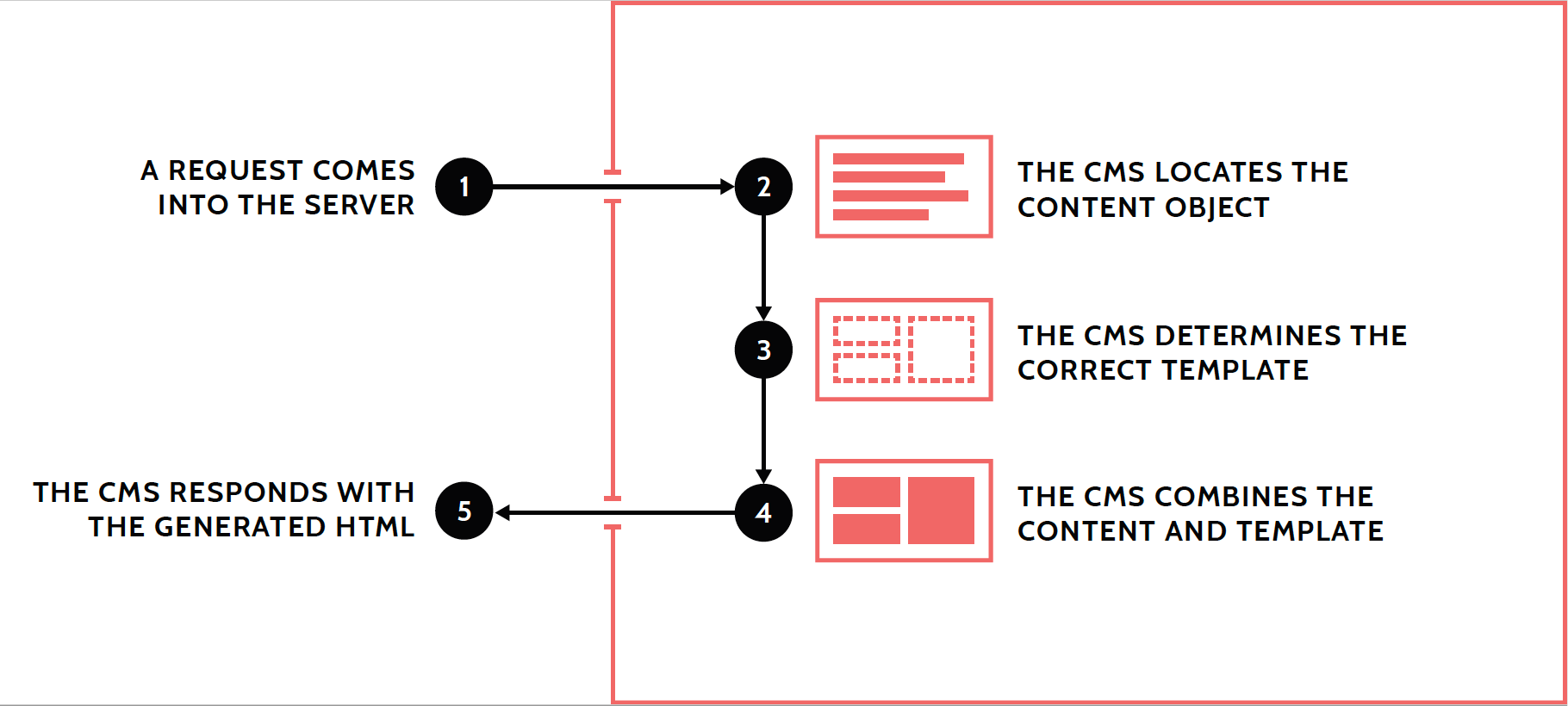
Figure 20.1: The request-response model within a content management system.
The process in steps 2, 3, and 4 is quite common in CMS architecture: map the URL to a content object, select a template, and execute the template against that content. The content object which is found in step 2 is known as the operative content object, meaning it’s the content object on which the request is “operating.”
For example:
- The URL
/news/tax-increase-is-comingis requested. - The CMS reviews that, searches, and locates News Article #437 as matching that URL.
- Checking its configuration, the CMS finds that News Article objects used the template in a file called
news-article.tpl. - The CMS executes
news-article.tplwith News Article #437 as the operative content object and gets a bunch of HTML in return. - The CMS sends that HTML as the response.
In most systems, there is always an operative content object. It might be a news article, a text page, a news article listing page – whatever. But there is usually a central, operative object on which each request is operating.
We noted in step 3 that the CMS needs to find a template. What template does it use? Usually, there’s a single template per content type – so News Articles have one template, Products have another template, etc. This makes sense, because templates need to know what type of content they’re operating against. You can’t execute the Author content for a Product, for instance. You have to know what data you have before you can output it.
Some systems have more complicated templating rules. It might default to a template per type, but there might be situations where you can specify a custom template for a particular object, for example. So all News Articles use the same template, except for News Article #437, which uses a special template, for whatever reason.
Template Languages
Template languages exist independently from CMSs. This means that knowledge of a particular template language can span different CMSs.
Remember our discussion of the “technology stack” earlier, and also remember that every CMS is written in an underlying programming language. Templates are “sub-languages” within those, that run “inside” those languages.
Here are some common languages for various underlying languages.
- .NET: Razor is very common, and is the default for most projects. Other languages are Fluid and Scriban.
- PHP: Twig is the most common language. Smarty is an older language, but still popular. And some systems simply use PHP itself (discussed more below).
- Java: Freemarker and Velocity.
- There are also templating languages that have versions for multiple programming languages, like Mustache.
Other Development Tasks
So far, the back-end developer has implemented the content model, designed and created the necessary content aggregations, roughed-in the content, and templated the output. This is the backbone of a CMS implementation. The bulk of the work exists in those tasks.
However, depending on your requirements, there are quite a few other details to be handled.
- Users, Groups, and Permissions: Everyone accesses a CMS in the form of a user (even if it’s a common user like “Anonymous”). Those users need to be created, organized into groups for manageability, and have permissions assigned. The goal is to protect your content, and protect users from themselves – no one should accidentally be able to do something they didn’t intend.
- Workflows and Content Operations: If the headcount of your editorial team is larger than one, then there might be a larger process to get content published – so-called content operations4. This might involve making sure content preview works the way it should, and work-flows and approval chains are in place to ensure more than one set of eyes looks at content before the public does.
- Localization: Many organizations publish content in more than one language. Your CMS will need to be configured to allow content translations in specific languages, and you’ll need to decide how to detect language requests5, and perhaps fallback through multiple language options for the best match. Templating might need to change as well – some languages are vertical, some are right-to-left, some are longer than others6, etc.
- Marketing Tools: One of the goals for a new CMS might have been to use some new-fangled marketing tools, like personalization and A/B testing. While these are more content challenges than technical challenges, they will still need to be enabled and configured.
- Page Composition: Some pages on your site will be composed rather than templated, which means editors create the pages by visually dragging managed components around a page surface. Special pages or templates will usually need to be created to support this. These pages often have zones or regions into which components can be placed and ordered7.
- Search: Sometimes search just works, but there are often lots of different configuration options available. You might want to hide some content from search, or boost other content. You might need to configure options like faceting or methods of finding related content.
- Reporting: Editors often need reporting about their content, ranging from simple usage analytics to quality checking and productivity reports – what images are no longer being used, where does a certain term appear in the content, how many content objects has each editor touched in the last thirty days, etc.
- Archiving: What happens to content when it’s not needed anymore? Does it get hidden? Deleted? Archived? What do those terms even mean in the context of this CMS? You need to plan for the entire lifecycle of content, and your CMS might need to be configured to handle obsolete content in a specific way. This includes content versions – how many versions of content should you retain, extended back how far in the past?
- Integration: As we discussed in an earlier chapter, your CMS might need to talk to other systems to provide content or functionality. These integrations need to be developed or installed and configured.
- Forms: Forms are handled differently depending on the system – in some, they’re a development task, while in others, they’re managed as content, purely by editors.
A Common Backbone
It’s hard to generalize about implementing the back-end of a content-managed website, since the tasks and challenges are wildly different based on requirements. What we’ve tried to do here is present the bare minimum of what would have to be done – a common backbone of work:
- Model Implementation
- Aggregation Implementation
- Content Rough-In
- Templating
We can state with some confidence that those four things have to be done in all implementations. Beyond that, every CMS and every implementation will be done a little differently.
Inputs and Outputs
The input to this process is almost the sum total of everything you’ve done so far. You’ll need your requirements, your integrations, your selected CMS, and at some point, your front-end implementation. The output is a running CMS implementation, ready for deployment.
The Big Picture
Back-end and front-end implementations often run in parallel. There’s a lot that a back-end team can do before they need the front-end team’s output for templating. And a lot of templating is trial-and-error. The two teams will need to communicate frequently, and go back and forth quite a bit to make some things work.
Back-end implementation is also often being done at the same time as content migration, which we’ll talk about later.
Staffing
You need a server-side development team, well-versed in your selected CMS and the underlying technology stack on which it runs.