Know Your Content
Summary
One of the challenges in rebuilding any website is figuring out what to do with the existing content. But before you can make any decisions, you simply need to know what it all is. And once it’s unearthed and exposed, then you need to decide what information is relevant and worth recording, determine a method to store this information, and decide how (or if ) you want to keep it updated over time.
Does This Apply?
If you have a website now, populated with content that you intend to keep, either in full or in part, then yes, you need to do this.
If you plan to throw everything away and start from scratch, then it really doesn’t matter what’s out there, other than as an evaluation tool to give you perspective on your new content. But this is rare. Also, if this is a new build rather than a rebuild, then there’s no content to inventory, and you can safely skip this phase.
Narrative
About a decade ago, one of the authors of this book moved out of his old house, which involved estimating the size of the moving truck they would need. The process took place over a few weeks: they packed up boxes, they hired professional packers, and they even did a test viewing of the truck sizes available to them.
They got a pretty big truck. Not the biggest, but pretty big. And, on moving day, after four hours of expert packing (and a lot of cursing), the truck was completely full. It felt like a job well done.
And then they remembered the garage.
Lawn chairs. Bikes. Tools. So much focus was placed on getting books and beds and other items from inside the house into the moving truck that the garage was completely overlooked. Thus began a frantic two hour period of securing a second truck. It was an added level of stress that could have been saved if they’d more accurately paid attention to the entire property, and not just the things on the inside.
Finding a new truck is simple when compared to the work that would go into reorganizing a site that’s already gone through design and development. Which is why, before you can make decisions about your content, you need to perform the supposedly simple act of determining what content you already have.
This process is rarely simple. Continuing the metaphor from above, it’s like moving out of a house you’ve lived in for fifty years. You spend a lot of time saying things like, “Where in the world did all of this come from?” and “I don’t even remember this,” and “Who put this here?”
This process is referred to as a “content inventory” or – perhaps erroneously – as a “content audit.” The terms are too often used interchangeably, but there is a difference:
- Content Inventory: The mechanical, objective process of cataloging all the available content, sometimes also known as a quantitative
- Content Audit: The editorial, subjective process of evaluating the inventoried content for its value to the goals of the website, and determining the future action to be taken on the content, sometimes
Under these definitions, a content inventory leads to a content audit. You can’t do an audit without an inventory, and an inventory often requires an audit in order to gain insight beyond simply knowing the scope of your available content. (Of course, different people call these things different things,1 because that’s how the sometimes messy world of the web works. The name doesn’t matter as much as the work being done.)

Episode 7: Know Your Content (w/ Paula Ladenburg Land)
Corey and Deane talk about Blend CEO Karla Santi’s recent selection as Small Business Person of the Year for South Dakota. Then, Paula Ladenburg Land, author of The Content Inventory and Audit Handbook and principal at Strategic Content LLC, joins the podcast to talk about content inventories and content audits, including what separates the two, when and how to worry about auditing, and her first ever content inventory, which arrived as a spreadsheet on one-and-a-half inches of printed paper.
The Content Inventory
Wouldn’t it be great if we didn’t have to do content inventories at all? In a perfect world, you would always know what content was published on your website, and you wouldn’t have to embark on a focused effort to figure this out. Either you’d have a perfect memory of every piece of content you’d ever created (unlikely), or you’d have some continual process that was constantly checking for new content and putting together some kind of report.
Of course, this isn’t the case, so you’ll often have to embark on an explicit accounting of content prior to a project. When you do this, there are fundamentally three problems you need to solve.
- How do you find all the content?
- What information should you catalog?
- How should you record this?
Finding Content
There are multiple options, each with advantages and disadvantages. Clearly, automation helps, and is required in anything beyond the simplest scenarios.
- A Manual Browse: Start at the home page, record information, click on a link, repeat. Obviously, this is inefficient and tedious and would break down on anything larger than a small site. However, in situations where it’s feasible, it can be comprehensive and generally results in a more intimate understanding of the content, as you – a living, breathing human being – evaluate every page while staring at it in a browser.
- An Automated Crawl: Using a web crawler, this provides the most comprehensive inventory. It is, by definition, visitor-centric – the crawler accesses your content like a visitor would, following links and ignoring inaccessible content. However, what you gain in automation, you lose in context – you end up creating a good chunk of work reviewing the crawl to add in more human observations.
- A CMS-Generated Report: If your CMS has good reporting tools, it might be possible to get a report of content. This is likely quick and comprehensive, but it might miss relationships between content, it will only capture limited information, and it suffers from the aforementioned problem of content which is published but technically orphaned.
- A CMS Export: Your CMS might have an export feature that will dump all content information to a serialized format like XML or JSON. If you have a developer available, this is essentially a CMS report which can be programmatically queried for further insights. Additionally, it’s likely more comprehensive than a report intended for reading, as an export will generally output all information about the content.
Recording Information
When forming the inventory, you’ll record more than just a title and URL. The following is information which can commonly be captured automatically, when using one of the methods above.
- ID: Some identifier for the content. This will often be a numeric ID from the CMS itself. (Yes, the URL itself could be considered an identifier, but it’s often handy to distill this down to something even more precise.)
- URL: The canonical2 URL under which the content is accessed.
- Title: The commonly accepted name or title of the content. Often, this will be the TITLE tag of a web page (minus any branding suffix, such as your organization name).
- Format: The digital format of the content, be it HTML, PDF, or an image type (though, it would be rare to inventory images unless they were intended to be accessed directly).
- Language: Often, the language can be determined from the URL, via the first segment (“/en/ about-us” compared to “/de/about-us”, for example). In other cases, the language will be returned as an HTTP response header or META tag.
- Size: The length of the content in bytes. This is occasionally handy to know when evaluating it.
- Response Time: With automated crawls, you can often obtain the number of milliseconds it took for the content to render.
- Assorted META Tags: Every site has a different assortment of META tags, and some are valuable to record. A tag of “Description” is often helpful, as are many of the Dublin Core3 tags (those beginning “dc:”).
Once this list has been formed through automated methods, some manual review and analysis should capture more subjective information. Some helpful information to find and record4:
- Content Subject: What is this content about? What product, topic, or category of information is represented here? (Don’t worry about defining these in advance. It’s easier to just note something about this specific piece of content, then go back through and make them consistent later.)
- Content Type: In a CMS, most all content has a designated, logical type, which dictates how that content is structured. Is this a simple text page, a news article, an employee profile, etc.? In many cases, this can be determined from the URL, or through simple analysis of the page. (Bonus points if you can persuade your developers to output the name of the CMS content type in a META tag you can automatically capture.)
- Owner: The human or organizational unit that is responsible for the disposition of the content. This is the person, group, or role who can make changes to the content, who can add similar content, and who can direct the content to be deleted.
- Velocity: How often the content changes, through edits to a single content element, or additions/deletion to a group of content (how often a new press release is published, for instance). When planning a content migration, for example, it’s very helpful to know if content changes every day, or only every five years.
- Analytics: If analytic metrics can be added automatically, this can be enormously valuable to evaluate the status of the content. A helpful set of analytics might be how many times the content has been viewed in the last seven days, thirty days, and three hundred and sixty-five days.
- HTML Analysis: Some systems will analyze the retrieved content for information. Does the HTML contain a FORM tag? How many headings does it contain? Is there embedded video? Is there a supporting image?
- Textual Analysis: Some tools offer more advanced text analysis for things like average reading level, presence or absence of keywords, etc.
Storing the Information
Even with a comprehensive list of URLs and a clear list of information to record, the process can break down over something as mundane as format. How a group of people collaborates on the inventory can have a huge impact on the quality of it over time or the quality of the ensuing audit.
Clearly, the natural tendency, then, is to put it in a spreadsheet. And this is fine, but – unless you’re working completely alone – it can’t be based on a singular file. Too many times, we see the results of an inventory in an Excel file, passed around from team member to team member. No one knows who has the latest version of the file, and multiple people are working on multiple copies. It’s a recipe for frustration and disaster.
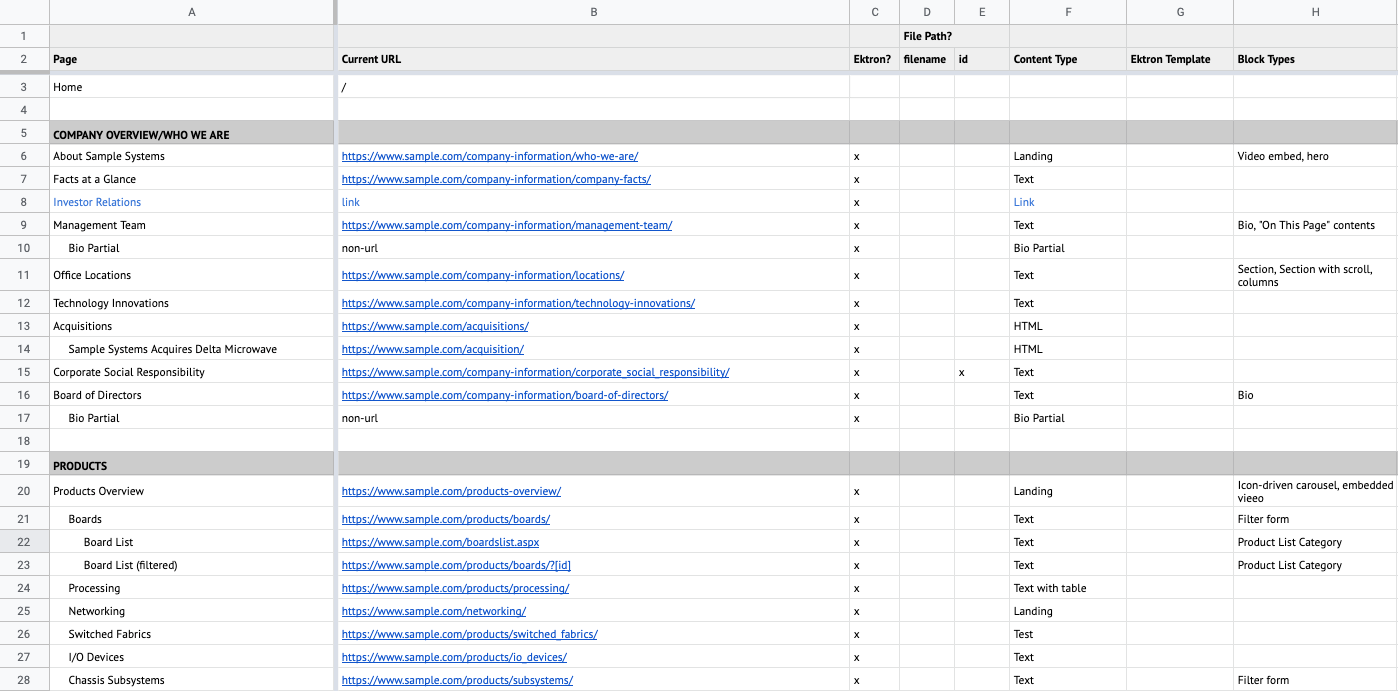
Figure 7.1: A content inventory created in Google Sheets.
Some options:
- The next most common option, by far, is some shared, concurrent Google Docs is perfect for this, as is the online version of Excel in Office 365. Other cloud-based tabular systems that allow concurrent access – Airtable, for instance – would also work.
- Record information about the inventory in the CMS itself. This takes a little work, but if your developer can add properties to a “page” content object (assuming your CMS supports one), then this information can be recorded directly inline with the content. Combine this with some custom reports, and you’re in an advantageous position. During migration, this information can be programmatically accessed to determine the disposition of content (ex: a “Do Not Migrate” checkbox could prompt an migration script to skip that content object.)
- Use an online tool specifically designed for inventories and decision making.
The key is that the inventory has to be a shared resource that the entire team can refer to and have faith in. The surest way for a team to lose interest in the effort behind an inventory is to have them lose faith in the integrity of the data it has generated.
The Content Audit
While a content inventory — quantitative by nature — is going to be limited by the information you can glean from a page and its workflow, a qualitative content audit can focus on connecting insight to the purpose and viability of that content. In other words, while a content inventory might help you understand how many news articles are on your site, the content audit helps you make decisions about which ones you should keep and whether they are important at all.
This might be an addition to the inventory spreadsheet; ratings, pivot tables, thoughts. Or, this might be a narrative analysis of the inventory with suggestions on improving content in more general ways. Regardless, your audit may include more subjective details, such as:
- Purpose: Why is this content here in the first place, and does it serve a purpose to any of our users?
- Goal Alignment: Does this content align with any of your current business goals?
- Next Steps: Does the page include a viable and understandable next step, or is this page the final step in a larger process?
- ROT Status: ROT stands for “redundant, outdated, or trivial,” and is shorthand for “we don’t need this content anymore and it should go away.” In an initial audit, you’re identifying these as they relate to business and user goals, and so having a column dedicated to ROT is key for your migration and overall content creation process. However, once the site is live and running, there’s no need to formally track ROT content: instead, you should simply remove or change this content.
- Accuracy: Is the content accurate, or does it need to be updated?
- Brand and Message Alignment: Is this content on-brand and does it align with your overall organizational message?
There could be dozens more, and there will be. And it’s worth noting that when it comes to auditing, you often don’t need to provide an exhaustive page-by-page look at every single piece of the content puzzle. Groups of products, past news articles, or data-driven content may need to be inventoried (for migration or maintenance needs) but do not always require a deep audit, either because they are only relevant as a group of content, or because they serve no further need beyond historical.
The audit is your time to make decisions and understand the purpose of content toward your goals. You need to do as much as you can to feel comfortable, and usually no more.
Inventory and Audit Maintenance: Keeping It Updated … or Not.
An inventory or audit is only current for a brief, fleeting moment, directly after it’s created – a photograph of your site as it was on the day you completed your work. Over time it “decays” as the underlying content changes. This might not be an issue if your website is fairly static and can be trusted not to change much. In other cases, the website is a moving target and might look remarkably different from day to day.
When considering how to keep up with additions and changes, the easiest way might be to simply not. In many cases, it’s acceptable to consider the inventory and audit as a snapshot of a particular moment in time.
For most sites, the content might change, but the structure won’t – articles or employee profiles are added and removed, but the basic concept of an article or an employee profile remains the same, and that’s enough. When making decisions about content, we tend to make those decisions based on type, and often not on the actual content.
One of the values of an inventory is the revelation of structure, which is usually more important than actual content. Do you really need to know about every single news release your company has made in the last ten years? Or do you just need to know that there’s a “bucket” of news releases at a certain spot in the site? What level of information do you need to make decisions about it?
This is contextual to your situation. Perhaps the question is, “Should we have a news release section at all on the new website?” If so, then you just need to know about the group of content and some general information about how it’s structured. In other cases, the question might be, “What news releases should we migrate to the new website?” In this case, you need to know about every single news release individually.
If the latter, then your ability to keep an inventory up-to-date over time depends on:
- The velocity of the content: How fast is content being added, removed, and changed?
- The distribution of the team: Do changes go through one person? Or is content managed by a newsroom with hundreds of reporters?
If your velocity is low and your team small (even solo), then just manually adjusting the inventory over time might be enough. In the opposite case, you will need one of the following:
- Some automatic notification of content changes. Many CMSs offer notification of subscription services to generate email alerts when content is changed.
- A service that monitors your website from the outside and notifies you when a new URL appears. There are services that will crawl websites on a continual basis and generate an alert when new content is found.
This is all complicated by whether you’ve moved past the inventory and into the more strategic audit, because now in addition to maintaining the location and structure of a page, you’re also continuously maintaining its goals, relevancy, and sometimes even its future.
Just remember that structure changes more slowly than actual content. The basic format of a news article might stay the same for years, while hundreds or thousands of actual news articles are created. In many cases, just knowing the structure of the content, where it’s located, and how it’s navigated is enough information.
Regardless of originating methods, data captured, and ability or method of keeping the inventory updated over time, your efforts from this phase should have generated some level of transparency around the content in your website. You should know roughly what content is on the site, how it is accessed, what type of information it constitutes, and who is responsible for its disposition.
Now that you know what you’ve got, let’s take a deeper look at what it’s doing.
Inputs and Outputs
The only input to this process is an existing website, and someone eager to use a spreadsheet.
The concrete output of this project is a content inventory document, in some form, as described above, or some kind of content audit document with analysis of current content and its connection to project goals. Sometimes, it’s both.
Additionally, a tacit output of this process is a shared understanding within the organization of the scope of current content, and the scope of new content needs. Content creation often gets short-changed, and an important result of this process is a newfound respect for the scope, schedule, and expense of what needs to be developed.
The Big Picture
This phase can be done before anything else. An inventory of the content on an existing website requires nothing but the decision to do it.
There’s a school of thought that says when someone announces, “We’re going to migrate the website,” that’s all you need to start a content inventory. You certainly don’t need to know anything about the new CMS, because you know you’ll be migrating into something, regardless of identifying the specific system.
In other cases, you might want to wait until you’ve developed a content plan, since that plan will identify the desired content for the new website, and those content needs might help you make decisions about what content to keep and what to discard.
At any rate, the phase needs to be completed early enough to allow enough time for new content to be created. Content creation takes time, and many a website has been implemented and then sat empty waiting for new content.
Staffing
This inventory is commonly completed by a content strategist or editor, as part of a larger engagement to plan the content of a new website. While the process of identifying URLs and pages is not particularly complex, making decisions about content will require an understanding of the organization and its goals.
Resources
Articles
- "Everyday Information Architecture: Auditing for Structure," A List Apart, by Lisa Maria Martin
- "The Content Strategy Term of the Week: Content Inventory," The Language of Content Strategy, by Paula Ladenburg Land
Books
- Content Audits and Inventories by Paula Ladenburg Land
- The Content Strategy Toolkit by Meghan Casey
- Content Strategy for the Web by Kristina Halvorson and Melissa Rach
- The Digital Crown by Ahava Liebtag
Presentations
- “Issues in Content Migration” by Deane Barker
Tools